一个简单的源码爬虫的实现
本文最后更新于:2025年10月20日 下午
一个简单的源代码爬虫的实现(基于python)
1.下载python和python的ide(懒,下载安装自行百度,本文专注源代码的实现)
2.Requsts简介
这是一个python库,其功能是用于爬网页数据。win用户在cmd中输入
pip install requsts
即可安装
Requests is an Apache2 Licensed HTTP library, written inPython, for human beings.
Python’s standard urllib2 module provides most ofthe HTTP capabilities you need, but the API is thoroughlybroken.It was built for a different time — and a different web. It requires anenormous amount of work (even method overrides) to perform the simplest oftasks.
Requests takes all of the work out of Python HTTP/1.1 — making your integrationwith web services seamless. There’s no need to manually add query strings toyour URLs, or to form-encode your POST data. Keep-alive and HTTP connectionpooling are 100% automatic, powered by urllib3,which is embedded within Requests.
------from http://www.python-requests.org/en/latest/
以上是来自Requsts官网的介绍
3.最简单的爬虫代码
直接通过get获取
import requests #导入Requsts包
html = requests.get('http://www.baidu.com')#通过get方法直接获取源码且存放在html中
print html.text #打印输出html变量中的数据
修改http头(解决中文乱码,仿真浏览器对抗反爬虫)
import requests
import re
#下面三行是编码转换的功能
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#hea是我们自己构造的一个字典,里面保存了user-agent。
#让目标网站误以为本程序是浏览器,并非爬虫。
#从网站的Requests Header中获取。【审查元素】
hea = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
html = requests.get('http://jp.tingroom.com/yuedu/yd300p/',headers = hea)
html.encoding = 'utf-8' #这一行是将编码转为utf-8否则中文会显示乱码。
print html.text
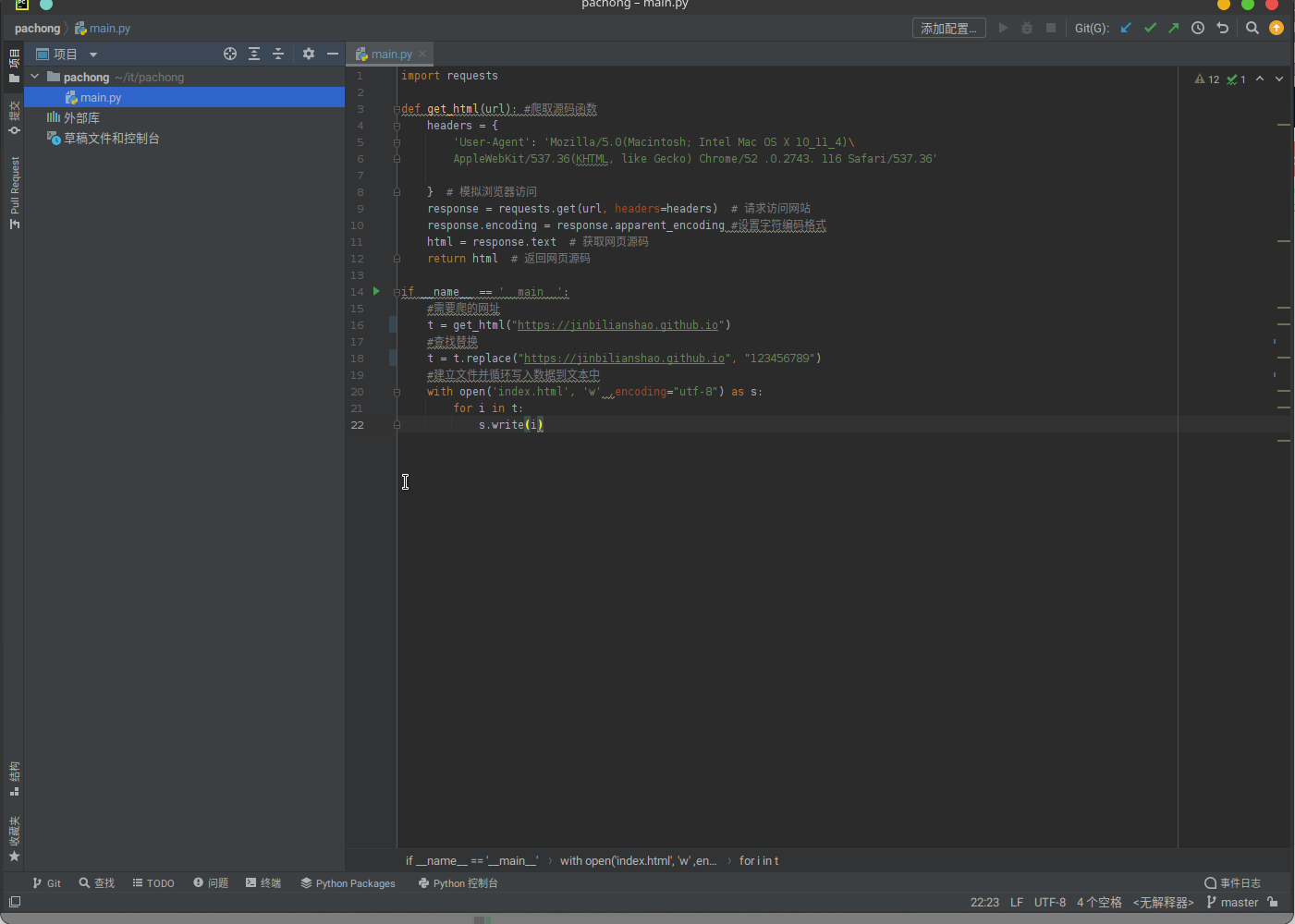
4.完整代码
import requests
def get_html(url): #爬取源码函数
headers = {
'User-Agent': 'Mozilla/5.0(Macintosh; Intel Mac OS X 10_11_4)\
AppleWebKit/537.36(KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36'
} # 模拟浏览器访问
response = requests.get(url, headers=headers) # 请求访问网站
response.encoding = response.apparent_encoding #设置字符编码格式
html = response.text # 获取网页源码
return html # 返回网页源码
if __name__ == '__main__':
#需要爬的网址
t = get_html("https://jinbilianshao.github.io")
#查找替换
t = t.replace("https://jinbilianshao.github.io", "123456789")
#建立文件并循环写入数据到文本中
with open('index.html', 'w' ,encoding="utf-8") as s:
for i in t:
s.write(i)
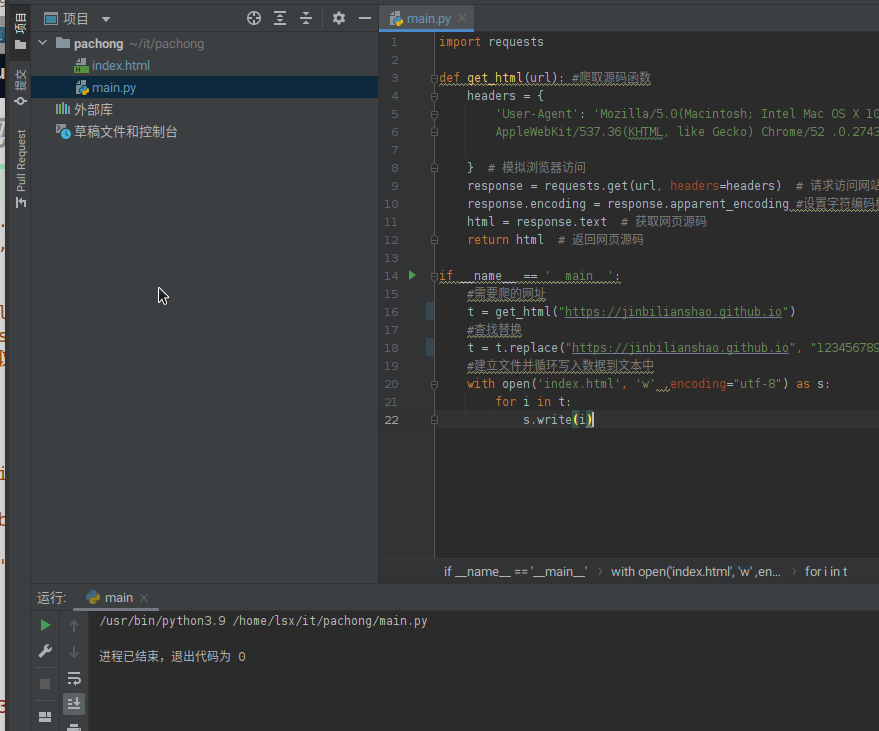
运行效果
可以看到多了一个index.html文件,这个文件就是爬下来的源文件
项目源码地址>>>https://github.com/JinBiLianShao/pachong
一个简单的源码爬虫的实现
https://jinbilianshao.github.io/2021/09/16/一个简单的源码爬虫的实现/